データ分析の後にやるべきこと
データ分析をした後に、特に何もせずにやりっぱなしになっていないでしょうか。
もしそうであるならば、その分析結果が正しかったのか、間違っていたのか、役に立たなかったのか、そもそも必要だったのか、といった評価を下すことはできているでしょうか。
効果の見えにくいデータ分析の仕事を繰り返していると、適切なフィードバックも得られず、スキルが停滞してしまう恐れもあります。
とりあえずXX分析を実施してまとめて報告した、だけを繰り返しても成果を出すのはなかなか厳しいと思われます。
一度分析して終わりではなく、その後その結果をもとに実際にアクションが実行されているのかどうか、それを定量的に可視化できないか、とか
どのようなアクションがとられて、その結果はどうだったのか効果はどれくらいだったのか、とか
少なくともデータ分析結果の実証や分析後のアクションの管理までやってみることをお勧めします。
ABC分析を例にして考えてみましょう。
ちなみにABC分析とは、売上金額の高い順に商品を並べ、累積構成比に応じてA、B、Cの3つのグループに分類するというものです。
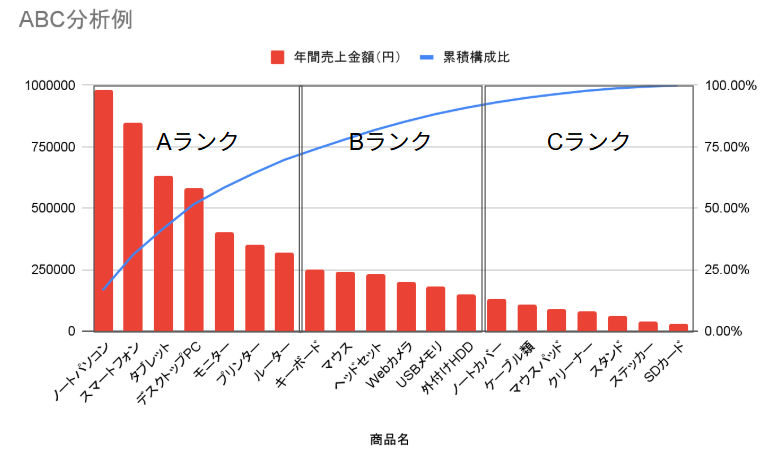
ABC分析によって、売上貢献の高いAランクの商品群が明らかになります。
データ分析者はこういった分析レポートを作成して実務担当者に報告するといった仕事をされていると思います。
ABC分析の場合、そもそも何のために行うのかというと「在庫管理」や「販売戦略」に活かすという目的が一般的には多いかと思います。
在庫管理で言えば、Aランク商品は常に在庫を切らさないように管理し、Bランク商品は必要に応じて、Cランク商品は在庫リスクの低い管理を行うといった感じです。
販売戦略の場合は、Aランク商品は重点的に販売促進を行い、Bランク商品は現状維持、Cランク商品は取り扱いを見直すなどの販売戦略を立てます。
データ分析は目的ありきなので、ABC分析のレポート作成の依頼を受ける際、こうした情報は事前に確認されているかもしれません。
しかし、上記のような在庫管理や販売戦略を実現するにはABCレポートだけで十分でしょうか?
確かにそもそもABCのランク分けをしないと始まらないので、最初にABCレポートを作成することは必要かもしれません。
しかしその後、Aランク商品を在庫を切らさないように管理するのであれば、在庫状況の可視化や在庫切れが発生した際の要因分析なども必要になりはしないでしょうか?
在庫切れしそうになっていないかを検知するアラート通知の仕組みもあったりすると良いかもしれませんね。
Aランク商品を重点的に販売促進するのであれば、本当にその後の販売施策でAランク商品の販売が伸びているか確認しなくても良いでしょうか?
そもそもどういった施策を計画しているのか、過去施策の分析やPoCなどを実施して効果の検証などを行わなくても大丈夫でしょうか。
データ活用というのは一度きりで終わるものではなく、継続的に実施するものです。
データ活用を意識してデータ分析を行うのであれば、レポートにまとめて報告して終わり、ではなく次に必要な分析やデータは何かを考え続けていくことが大事です。
それを繰り返すことで、データ活用を阻害するポイントや原因はどこか、データ活用を促進するために何をすれば良いか、なども見えてくるようになると思います。
依頼された単発のデータ分析をこなすだけでなく、ある程度のロードマップを最初に描いて依頼者と中長期的な関わりを提案してみるのもお勧めです。
自らフィードバックを得ようとしたり、PDCAにつながるような形に持っていこうとすると成長機会も多く得られるのではないかと思います。
KPIの運用管理方法
KPIの「設計方法」は巷にたくさん情報がころがっていると思います。
基本的には以下のポイントにまとめられると思います
- 不適切なKPIを設定しないようにする
そもそも自分たちで改善できない指標であれば意味がないので、基本的にコントロール可能な指標である必要があります。
外部要因の影響を強く受ける指標であれば、当人たちがいくら頑張ってもその外部要因次第になってしまうので、運否天賦のようになってしまい、KPIマネジメントとは別物になってしまいます。
また改善可能な指標であっても、KGIと因果関係が全然なければ、改善したところであまり意味がないことになります。
いくらKPIを達成したところで、肝心のKGIが達成されないのであればあまり評価もされないでしょう。
なので、KGIにそれなりの影響のある指標であることも必要です。
- 運用しないKPIを設定しないようにする
KPIを考える際、色々な数値を見たいということで非常にたくさんの指標がリストアップされることがあります。
そうすると上記で述べた不適切な指標も混ざりやすくなりますし、データを準備する側・報告する側・管理する側みなの負荷も高まり、ひとつひとつの指標の重要性や意義が薄まってしまいます。
結果として、指標が多くなればなるほど管理しきれなくなり、やがてそのうちほとんどチェックされなくなります。
また基準値を決めづらいKPIも運用に堪えられなくなります。
例えば、売上 = 顧客数 × 顧客単価 の図式から
KPIとして、顧客数1万人、顧客単価1万円と設定したとします
両方達成すると1億円の売上となりますが、KGIが1億円ならば別に顧客数5千人、顧客単価2万円でも良いわけです。
逆に顧客単価が5000円に落ち込んでいるなら、KGI達成のためには2万人の顧客数が必要になります。
なので、顧客数だけを見ても現状の進捗および次にどうすべきかの判断は困難ではないでしょうか。
結局はKGIである売上だけが着目され、このような指標はただ参考値として見るだけになってしまうでしょう。
KPIの運用管理方法
上記で述べた内容に気を付ければ、KPIマネジメントはうまく進められるのでしょうか。
自分のこれまでの経験上、おそらくもう少し気を付けるべきポイントがあるかと思うので、それについて紹介してみたいと思います。
まずは、運用管理の体制をきちんと整えることが必要かと思います。
- KPI運用管理範囲を明確にすること
本来はKPI設計を行った後で、各KPIとそれを管理する部署を考慮して、組織の組成をするというのがより理想かと思います。
しかし、色々な事情でそうなっていない場合、部署や個人ごとの業務範囲や目標(評価項目)はそれぞれの観点で設定されてしまうと思いますので、KPIの観点からするとちぐはぐなものになってしまったり、全体最適でないものになってしまいやすくなります。
とはいえ、いきなりそれらを変えることも難しいでしょうから、まずは各KPIごとにその運用管理に関わるべき部署や担当を明確にしてみることから必要でしょう。(部署横断のバーチャルなチームにするのも良いと思います)
自分の仕事はこのKPIに関連するものだけれど、特に目標を持たされてなかったり管理指示を受けてなかったりすると、自分事にするのは難しいものかと思います。
また、管理範囲は管理できない範囲で分けないように注意してください。
例えば、売上 = 顧客数 × 顧客単価 の図式から
顧客数を管理するチームと、顧客単価を管理するチームに分けたりすると、前者のチームはとにかく顧客数を増やすのがミッションなので、顧客単価が低かろうと気にしなくてよいことになり、後者のチームの足を引っ張ることにもなりかねません。
なので、この場合もし分けるならば顧客の種別ごとなどの方が良いかと思います(業界別、チャネル別、規模別など)
- KPI運用管理の責任者を設置すること
KPIごとに運用管理範囲が明確になっても、その中でKPI管理をリードする責任者がいないと運用管理がうまく回りません。
KPIをモニタリングできるダッシュボードが用意され、あとはメンバーそれぞれが見たいときに見るだけであれば、はたして共通の目標として運用されるでしょうか
きちんとチェックして改善に活かす人はそうするかもしれませんが、気が向いたときに見るだけという人もいるかもしれません。
KPI管理が「人による」という属人的なものになってしまいます。
そうならないよう責任者を設置し、改善のための活動を先導してもらう必要があります。
できれば責任者にはKPI管理の業務を評価にきちんと連動させ、改善する際にそのためのアクションを推進できる権限を持たせる必要もあるでしょう。
- 定期的にKPIの確認・相談の場を設定すること
管理者が決まればあとはその人に丸投げしても良いでしょうか。
チームマネジメントにおいても定期的に進捗確認や1on1などを実施されると思いますので、同様にステークホルダーが集まって進捗確認・相談する場があった方が、属人的な管理を予防し、客観性を踏まえた管理になりやすくなります。
なんだ当たり前じゃないかと思われるかもしれませんが、そうした場を設けずにKPI運用されているケースも結構あるようです。
普段の定例会議などの場で確認するのはKGIだけで、KGIが悪化しているなどの事情があれば、そのときに参考資料としてKPI(の一部)を見るくらい、などはよくあるようです。
- KPIが悪化した際にとるべきアクションを明確にしておくこと
こちらはKPIの設計にも関連しますが、KPIがコントロール可能な指標ならば、どのようにコントロールすべきかも明白なはずです。
そうなるとKPIをもとにアクションプランが立てられることになるので、KPIが悪化した際に何が原因なのか、どうすれば改善できるのかも明確になります。
報告の場でKPIが悪化していることが明らかになった際、このあと原因を調べますで終わると対応が遅くなり、結局何もできなかったなんてこともよくある話です。
少し難しいのは、悪化要因がリソース不足のケースですね。
イレギュラーな事情により、KPIを改善するためのリソース(人、物、金、時間)が不足してしまった場合、リカバリーするのは容易ではないかもしれません。
もし下方修正が必要になりそうでも、早めにステークホルダーに連携すれば、他のKPIでカバーできたりリソース追加してもらえるかもしれないので、その根拠をきちんと示せるようにしておくのは大切でしょう。
- いきなり本運用せずにまずはトライアル運用をしてみること
いきなり最初から最適なKPIを決めて運用管理できるようになるかというとなかなか厳しいかと思います。
事前に最適な設計を行おうとしても時間や労力をかけても、やってみないとわからないとか運用してはじめて気が付くこともあったりするものです。
そのためまずはトライアル運用してみることがおすすめです。
トライアルという位置づけならば、改善の意見も出しやすくなりますし、途中で軌道修正の対応もしやすくなります。
本運用では既に運用が始まっているので途中で軌道修正しようにも困難だったりすることが多いようです。
また本運用だとその年度の運用管理が終了してすぐまた翌年度の運用が始まるということになり、振り返りや反省・改善がなされないままになることもよくあります。
結果的に同じ失敗を繰り返したり、KPIマネジメントを途中であきらめてしまうケースもよく聞く話です。
最後に
KPIの運用管理方法について、私のこれまでの経験を振り返ってみてとりあえず思いついたものを書き連ねてみました。
当然これで全てではないでしょうし、また気づいたことがあれば記事にするかもしれません。
KPの運用管理は「これが正解!」といった事例があまり世の中に出回らないので、結構いい加減な内容のものもよく聞きます。
上手くいかない場合は、設計に問題があるケースも多いと思いますが、実は運用管理もきちんと考慮されていないと、設計時の問題に気づけず同じミスを繰り返してしまうといったことも多いのではないかと思います。
つまり、PDCAが回るようになっておらず、延々とPDまたはPDCを繰り返しているようなイメージですね。
数年前からXXOpsという言葉をあちこちで聞くようになりましたが、オペレーション(運用)まで含めて考えることが重視されるようになった表れなのではないでしょうか。
データアナリストの社内キャリア
従業員の仕事内容や給与を決めるのにグレード(等級)制度を使っている企業は多いと思います。
私が勤めている会社もグレードが導入されています。
先日人事制度の大きな見直しがなされることになり、合わせて同時にグレードの基準にも見直しが入ることになりました。
その中で私もデータアナリストの職種に関するグレードの設計を担当しました。
といったことがあったので、改めてデータアナリストのキャリア(社内)を今回のトピックに選んでみました。
そもそもグレードの高低はどのように決めるべきなのでしょうか?
一般的なキャリアアップの観点では、「スキルレベル」がよく話題に上がると思います。
例えばデータサイエンティストならばデータサイエンティスト協会というところがスキルレベルの定義をしていますね。

https://www.datascientist.or.jp/common/docs/10thsymp_skill.pdf
上記スライドは概要ですが、実際は各レベルごとにビジネス力・データサイエンス力・データエンジニアリング力の観点で細かくチェック項目が用意されています。
(チェックリストの細かい内容が気になる方はこちらまで)
ただ、企業内の人事評価と紐づくグレードでは、上記で言えば「ビジネス力」が特に強く影響されることが多いかと思います。
ニッチなスキルや専門知識をどれだけ持っているかなどは関係なくて、基本的にはあくまで「実績ベース」です。
そして上記のスライドでも記載されている通り、対応できる課題の事業規模の大きさのようなイメージなどで実績が測られます。
少々乱暴に言えば、シニアとジュニアの違いというのは、知識や経験の多寡ではなく、できることの規模や影響の大きさです。
もちろん大きな影響のある仕事を行うにはスキルや知識なども必要になりますが、あくまでそれらは「手段に過ぎない」ので、それらがあるから評価が上がるといった評価軸ではないということです。
逆に言えば、当たり前ですが知識や技術の単なるコレクターはあまり評価されず、それらを活かして成果を出せる人が評価されるということですね。
データサイエンティストのスライドを例にしてみます。
プロジェクトの中のいちテーマの仕事をやり遂げることができれば、アシスタントとして評価されます。
担当プロジェクト全体をゴールに導くことができれば、アソシエイトとして評価されます。
フル・データサイエンティストならば、対象組織全体の課題を解決できることが求められます。
「対象組織全体の課題の解決」というとちょっと抽象的でわかりにくいですが、以下のチェックリストの項目(一部抜粋)は参考になるでしょう。
・初見の事業領域に向かい合う場合や、スコープが複数の事業にまた がる場合であっても本質的な課題を見出し、構造化・深掘りができる
・入り組んだステークホルダー構造の中で、Win-Winの形で価値を設計・創造し、そこからの発展を見据えた仕込みと推進するハブとしての役割を担うことができる
・プロフェッショナルからなる複数のチームによるプロジェクトの役割、目標を定義、リスクをマネージしつつ推進し、全体としてのアウトプットにコミットできると共に、メンバーを育成、さらには持続的な育成システムを作り出すことができる
フル(シニア)クラスだと、そもそも上記のような仕事を任されないと評価の土台に上がらないですし、上記の仕事をやり遂げるには総合的かつタフなビジネススキルが必要になります。
データ活用で実績を積む場合、データを分析して何らかの示唆を出す程度では、全体の中のごく一部の作業を担っただけでしかないので、あまり大した実績とはみなされないでしょう。
独り立ちとされるアソシエイトのレベルでも、担当プロジェクト全体をやり遂げることが求められます。
つまり、プロジェクトの企画・提案から管理・遂行まで対応できることが必要です。
私が今まで見てきたメンバーの様子では、そもそもきちんとした企画を立てるところが結構ハードルが高いようです。
課題をヒアリングするだけで終わらず、その課題の本質的な原因を構造的に捉え、解決のために「具体的に」何をどうすれば良いのか、現実的かつ説得力のあるプランを作れる、
あるいは自ら事業的に効果/意味のあるゴール設定を行い、そのために必要なタスクの分解・要件定義をロジカルに作成できる人、などはあまり多くないように思います。
さらにステークホルダー(関わる部署/メンバー等)が多くなればなるほど諸々が複雑化します。
その調整・整理がうまくできるとプロジェクトの成功率が上がるので、そういう人材も高評価でしょう。
(この辺りの経験や実績が豊富で自信のある方がいれば、是非ともうちの会社に来て欲しいくらいです)
データサイエンティストなどは専門性の高い職業のような印象があるかと思いますが、高く評価される方は専門性よりも実績が認められているのだろうと思います。
データアナリストもその点は同様で、どれだけ実績を上げたか(同等の実績を上げられるとみなされるか)が評価軸とされますし、そうあるべきでしょう。
ということで、データアナリストのキャリアアップ(社内)のちょっとした参考にでもなれば幸いです。
※一応ですが、今回の話はあくまで事業会社のデータアナリストを対象とした社内におけるキャリアです
※また途中でジョブチェンジすることも対象外です(データアナリストを続ける上でのキャリアップです)
中学入試で出題されたデータサイエンス問題_解答編
前回の記事の続きです。
まだ読んでない方はそちらから読んでみてね。
まずは改めて前回扱った問題を掲載します。
(問)
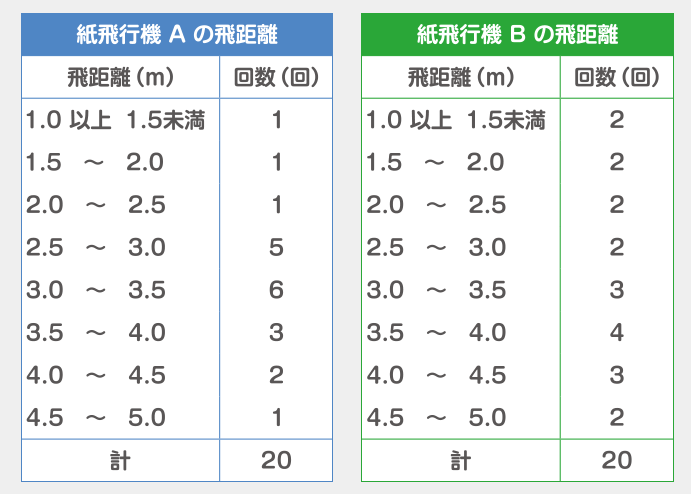
頌子さんは、紙飛行機の飛距離を競う大会で使用するために紙飛行機A、Bを作りました。
大会では紙飛行機を1回だけ飛ばします。
下の表は、どちらの紙飛行機を大会で使用するか決めるため、それぞれ20回ずつ飛ばした結果を表しています。
それぞれの飛距離の平均を求めたところ、平均は等しくなりました。
あなたなら頌子さんにA、Bどちらの紙飛行機をすすめますか。
どちらを選んでも構いませんが、2つの表を比較して、選んだ理由を数を用いて具体的に答えなさい。
2024年09月 頌栄女子学院中学校【算数】 | 日能研 シカクいアタマをマルくする。
問題文を読むといくつかの前提条件が書かれていますが、ちょっと足りない気がします。
頌子さんは紙飛行機の飛距離を競う大会に出るようですが、そこで優勝したいと思っているのか、上位に入りたいと思っているのか、下位でなければ良いと思っているのか、目的が不明です。
仮に目的は大会で優勝すること(参加者の中で一番遠くに飛ばすこと)としましょう。
その場合、他の参加者の紙飛行機はどれくらいの飛距離を出すのかは非常に気になります。
例えば参加者全体の優勝ラインがもしも10m以上であるならば、AもBも最大で5mしか飛ばないと思われるので、そもそも頒子さんはAとBのどちらを選ぼうと優勝はほぼ無理でしょう。
他者の紙飛行機の飛距離情報がが不明であれば、優勝を目指せるかどうかも判断できません。
なので、紙飛行機はどの参加者もAまたはBと同性能のものしか使えないという前提のもと考えることにしてみましょう。
ちなみにこうした「目的」や「前提」がないとそれに沿った適切なデータ分析はできず、当てずっぽうでまぐれ当たり狙いのデータ分析になってしまうので、まずはそれらを整える必要があります。
さてこの場合、みなさんならどのような分析をして、頌子さんにどちらの紙飛行機を勧めるでしょうか。
(シンキングタイム)
。。。
。。
。
では私の解答を紹介してみます。
自分ならBを勧めます。
優勝となる最長距離がもし3.5~5mの場合、その距離まで飛ぶ確率はBの方が高いからです。(Aは30%、Bは45%)
もちろん最長距離が3.5~5mになるとは限りませんが、そうなる確率も一応計算してみましょう。
もし、AとBひとりずつしか参加者がいなかった場合、最長の飛距離が3.5m以上になる確率は61.5%です。(30% + 70% x 45%)
一方最長距離が3.5m未満になる確率は38.5%です。
なお問題文に参加者の人数が書かれていないのですが、大会なので参加者はおそらくもっとたくさんいると思われます。
もしAとBそれぞれ5人ずつ参加するとなると、最長の飛距離が3.5m未満になる確率は1%未満とさらに低くなります。(38.5%の5乗)
ということで、優勝距離が3.5m以上になる可能性は非常に高いと思われます。
なお、目的が優勝すること(参加者の中で一番遠くに飛ばすこと)ではなかったり、前提条件も異なっていれば、当然分析結果や結論も違ってくる可能性はあります。
(例えば最下位にはなりたくないという目的であれば、お勧めすべきはAだったりします。)
データ分析ではまず目的を明確にすることや、前提条件を整え課題を構造化して捉えることが大事と言われるのは、こうした理由もあったりします。
ということで、きちんと目的を踏まえた上でそれを叶えるために客観的で納得性のある根拠を提示するような回答でないと、〇にはできないだろうと思われます。
データを見てから考える癖がついてしまうと、「目的や前提は何か」ということに意識が向かなくなる可能性が高くなります。
目的や前提条件が不明な状態であれば、自らそれを調査したり、確認するといったことが必要です。
データはFACTを教えてくれますが、活用方法は教えてくれません。
若い人たちには、データを処理したり、読み解くといったスキルだけではなく、活用するためのスキルも学んでほしいものですね。
中学入試で出題されたデータサイエンス問題
日能研にて、2024年の頌栄女子学院中学校入試問題が紹介されていました。
『シカクいアタマをマルくする。』シリーズのうちの一題として選ばれた問題とのことです。
日能研がなぜこの問題を選んだのかについては以下のように書かれています。
近年、私たちを取り巻く社会では、統計学、データサイエンス等の重要性が声高に叫ばれています。ビッグデータの活用、データマイニング、デジタルデータの安全性など、枚挙に暇がありません。この問題からは、算数を通して、そのような社会で必要とされていることと子どもたちとのつながりが感じられます。
ちなみにデータサイエンス問題とタイトルでは書きましたが、中学入試なのであくまで算数の範囲の問題です、念のため
その問題はこちらです。
(問)
頌子さんは、紙飛行機の飛距離を競う大会で使用するために紙飛行機A、Bを作りました。
大会では紙飛行機を1回だけ飛ばします。
下の表は、どちらの紙飛行機を大会で使用するか決めるため、それぞれ20回ずつ飛ばした結果を表しています。
それぞれの飛距離の平均を求めたところ、平均は等しくなりました。
あなたなら頌子さんにA、Bどちらの紙飛行機をすすめますか。
どちらを選んでも構いませんが、2つの表を比較して、選んだ理由を数を用いて具体的に答えなさい。
2024年09月 頌栄女子学院中学校【算数】 | 日能研 シカクいアタマをマルくする。
さて、みなさんならばどのような回答をされるでしょうか。
この問題はデータ活用やデータによる意思決定というものを考える上で、非常に興味深い良問ではないかと思います。
じっくり考えて頂いても良いのですが、日能研による解答例と解説も合わせて紹介します。
この解答例と解説についても、妥当かどうか考えてみて下さい。
<<解説>>
20回すべてで考えると、飛距離の平均は等しくなるので、飛距離の平均はすすめる根拠にはなりません。理由を説明する方針は、大きく分けると、
①ある順位について、その大小を考える、
②ある区間までの回数に着目する、
③代表値を利用して考える などが考えられます。ここでは、考え方の例をいくつか示します。
<<解答例>>
例1 Aを選ぶ
≪理由≫ Aは安定しているが最頻値は低めで、Bは最頻値は高いが不安定である。1回しか飛ばせないことを考えると、失敗は許されないのでBよりもAを選んだ方がよい。例2 Bを選ぶ
≪理由≫ 3.5m以上飛んだ回数がAは6回で、Bは9回だから、Bの方が飛距離が長い可能性が高いと考えられるから。
データを元にどのような意思決定を行うべきかしっかり考えてもらいたいという思いを込めて、小学生の解答ならば上記でも〇で良いのかもしれません。
しかし、もしこれが小学生ではなく、現役のデータ分析を生業にしている人の解答であればいかがでしょうか。
私が採点官ならば、ちょっと〇にはしたくないなと思います。
なぜならば、この場合はどのデータに着目するかで解答が変わってしまうものなので、意思決定の判断材料にならないからです。
解説の内容と例1と例2を二つとも頌子さん(意思決定者)に提示したとして、果たして頌子さんはAが良いのか、Bが良いのか選べるでしょうか。
またどちらか片方の例しか頌子さんに提示しない場合、それもあまり好ましくありません。
あなたが恣意的に頌子さんの意思決定を左右できてしまうことになるからです。
例えばAを選ばせたいならば例1のような解答を行い、Bを選ばせたいならば例2のような解答を行えば、意思決定者の判断を誘導しやすくなります。
つまり上記の解答例では、客観性な根拠を元にした意思決定ができないということで、〇にはできないなと思うのです。
ではどのような解答をすべきなのでしょうか。
私の考えは次回ブログで紹介させていただこうと思います。
ということで、少しお待たせすることになり恐縮ですが、もし気になる方がいれば次回の記事まで乞うご期待といういうことで。m(__)m
結婚している人のほうが幸福度は高いのか - データ分析による検証方法の考察
以下の記事を読んで「これはデータ分析事例として興味深い」と思い、私も今回記事にしてみました。
紹介した記事では、結婚している人のほうが幸福度は高い、として以下のグラフが紹介されています。

グラフを見ると確かに、男女とも未婚よりも既婚の方が幸福度は高くなっています。
一般論としても未婚より既婚の方が幸福度は高そうだという話も聞かなくもないので、違和感ない方も多いかもしれません。
ただし、このグラフから「結婚している人のほうが幸福度は高い」と言い切ってしまって果たして良いのでしょうか?
データ分析してる人ならば、因果関係ではなくただの相関関係かもしれない、と考えたりするのではないでしょうか。
グラフでは既婚と未婚に分かれていますが、既にその時点でバイアスがかかっている可能性があります。
例えば、男性の既婚と未婚では、年収を比べると数十万円から100万円以上の差があるというデータもあります。
【未婚・既婚男性の年収分布】中央値、割合、都道府県別年収がわかる|年収ガイド
上記は婚活サイトのデータなので20~30代後半までのデータしかありませんが、少なくとも20~30代の男性に限って言えば、既婚と未婚で年収に差があるので、この違いが幸福度に影響を与えているのかもしれません。
もし年収が同じグループの既婚・未婚同士で幸福度を比較したデータがあれば、年収の影響を除外した分析が可能になります。
もしそうしたデータにおいても、いずれのグループでも既婚の方が幸福度が高いというデータがあったならば、「結婚している方が幸福度が高い」という説にうなずく人も増えるのではないでしょうか。
なお他にも幸福度に影響を与えそうな要素を考えてみると、色々ありそうです。
例えば、仲の良い友人の数、所属しているコミュニティの数、趣味の数、健康状態、などなど。。。
以上の要素においても、もし既婚と未婚で偏りが出ているならば、幸福度はそちらの要素の影響が混ざっている可能性も考えられます。
とはいえどこまでこうした要素を除外して分析できるか、というのは非常に難しいかもしれません。
ランダムサンプリングによるABテストを複数繰り返し、その結果をもってしても、完全に偏りを排除できているとは言えないかもしれません。
なのである意味きりがないものでもあります。
実現場ではコストや時間的な制約などもあるでしょうから、分析者によってもどこまで納得性を追求するかはまちまちでしょう。
しかし、分析者であれば分析対象が偏っていないか疑う意識は常に持っておきたいものです。
さて、ここからもう少しこのテーマについて深堀りしてみましょう。
先のデータにより、婚姻状況は幸福度に好影響を与えていることがわかっています。(ただの相関で婚姻とは別の交絡因子の影響かもしれませんが)
それは「なぜ」なのでしょうか?
結婚すると伴侶や子供といった家族が増えます。
大切な家族がいれば幸福度が上がるのでしょうか?
であればそうした家族が多くなると、幸福度はさらに上がるのでしょうか?
ひょっとすると、結婚していなくても仲の良い兄弟や親戚がいれば幸福度は上がるのでしょうか?
いやいっそ家族や親戚でなくても、仲の良い友人や頼りになる先輩、慕ってくれる後輩、彼氏彼女、尊敬できる人などがいれば幸福度は同じように上がるのでしょうか?
こうして考えていくと「他者との関係性」といったものが幸福度に影響を与えているのではないだろうかという仮説を立てることができます。
このようにいわゆる帰納法のような考え方をすると、より高い視座や抽象性を上げた仮説を考えることができるようになります。
また「他者との関係性」以外の要素も考えてみましょう。
人は欲求が満たされると幸福を感じるものかと思います。
欲求というと「マズローの欲求階層説」なんかは有名ですね。

【図解】マズローの欲求階層説(5段階欲求)とは?わかりやすく解説
先ほどの「他者との関係性」は承認欲求や社会的欲求などに当たる部分なのかもしれません。
他の階層などの欲求が満たされると、結婚以外にも幸福度が高められるヒントが見つかりそうです。
例えば、お腹がすいてるときにおいしいごはんを十分食べられれば幸福を感じることでしょう。
例えば、継続的な収入が得られていないときに、安定な職につくことができれば幸福を感じる人もいるでしょう。
特に昔のように貧しい人が多く社会制度も整っておらず治安も良くない世の中などであれば、生理的欲求や安全の欲求が満たされることで大きな幸福を感じる人も多かったのではないかと思います。
またさらに自己実現や個人を越えた社会的貢献などを果たした際にも、幸福度が上がる可能性は高そうです。
そもそもこうした幸福度の高低のデータに注目が集まるのは、やはりみんな幸福度を上げたいと思っていて、どうすれば良いのだろうかと考えたりするからではないでしょうか。
幸福度を上げるためのヒントになるような分析結果を導くことができると、分析の評価も高まるのではないかと思います。
分析者は、分析結果がどのような効果や評価をもたらすかも意識した上で、どこまでの分析を行うか常に考えるようにしたいものですね。
データ分析をプロジェクトとして行うことのすすめ
データ分析は、いち担当者が個々に実施するよりも、プロジェクトとして複数名集まって実施する方がお勧めです。
個人でやる分析は、その人によるので非常に属人的です。
実は間違っているかもしれないし(しかもそれに気づいておらず正しいと勘違いしていることも)、分析結果を特に何にも活用しない(できない)なんてことも多々あります。
そもそも分析をしない(途中でやめる)こともざらにあるでしょう。
もし何らかの効果が見られたとしても、その人の業務に活かされるくらいで、広がりもあまり期待できなさそうです。
以上のように、効果が出る可能性も低く、効果が出たとしても限定的であろうといった感じかと思います。
一方、プロジェクト化するとどうなるか
プロジェクトを始める際には、ゴールや目的を設定しメンバで共有します。
納期内に如何にそのゴールを達成するか、ロードマップやWBSを作成してそれに則ってタスクをこなします。
よって途中でやめるということはほとんどないですし、プロジェクトの目的もきちんと定められてからスタートするので、意味のある分析を行いやすくなります。(とりあえずデータを見てから次にどうするか考える、ということにはならなくなる)
定期的にあるいは都度レビュープロセスが入るので、ミスも起こりにくくなります。
またアウトプットは一定の品質が担保されるため、二次利用や横展開も可能です。(元々影響範囲も考慮されたゴールが設定されることが多いです)
デメリットとしては、プロジェクトの前準備に一定の時間が必要なので、クイックに結果を出すのは難しいこと、
あとは、複数名(データ分析人材以外も含めて)が絡むことになるので個人で行う場合と比べて、人的コストは大きくなります。
ということで、データ分析できてないと感じておられる企業では、個々人にスキルをつけてもらって頑張ってもらうやり方よりも、プロジェクト化する形をお勧めします。(できれば経営層ないしは上級管理職層もきちんと関わられる形が望ましいと思います)
なお、データ分析プロジェクトでは目的を「データ分析すること」にしてしまうと、アウトプットを見て皆が感想を述べて終わり、となるのでお勧めしません。
私の観測範囲では、なぜかデータ分析という手段を目的にしてしまっているプロジェクトがよく見られるので、結構この失敗例は多いと感じています。
プロジェクト名が「XX分析プロジェクト」とかなっていると要注意です。(タイトルに手段が入っていると、目的と入れ替わってしまう可能性が高いのでは?と感じます)
ではどういう目的を設定すれば良いのでしょうか
基本的には「データを分析した後どうするのか」をきちんと言語化して、その内容達成までをゴールにする方が良いかと思います
例えば、「需要予測をして適正な在庫数を見積もり、廃棄商品を削減する」のであれば、「廃棄商品の削減」がゴールです。
なお「廃棄商品の削減」をゴールとすると、そもそも発注数を抑えるという手段も出てしまうので、売上は維持するという前提条件をつけたり、
そもそも廃棄されにくい商品だとコスト削減効果も低かったりするので、一定期間内に一定数以上廃棄されている商品にスコープを絞るなどといったことを決める必要もあります。
次にそのゴールを達成するためのプロセス(進め方)を策定します。
データが関わる部分としては、「現状把握」や「需要予測」などがありますが、当然それらだけでプロセスは完成しません。
廃棄数の多い商品は、需要に対して供給が上回っているということなので、そのバランスをどう是正するかのプロセスも必要です。
やり方は色々あるかと思いますが、需要に対して適切な供給を行う方針にした場合、発注数を改善することになります。
現状の発注の仕組みの課題を明確にするために、現状の発注数はどのように決まっているのか、なぜ過剰な発注をしてしまうのかも明確にする必要があるでしょう。
当然この課題解決もプロセスに含める必要があります。
業務プロセスの改善やシステム改修も必要になりそうであれば、それらのプロセスや担当も巻き込むことになるでしょう。
あとは、実際に課題解決できるかどうか、実験的に効果検証をしてみるとかも必要になってくるかもしれませんね。
プロセスがある程度見えてきたら、それに必要な人員の見積もり、アサイン調整もできるようになるかと思います。
といった感じで、プロジェクト「開始前」に以上のようなことを一通り決めます。
以上のようなことを決めないままプロジェクトをスタートしてしまうと、プロジェクトの失敗確率が上がってしまうでしょう。
さて、データ分析人材はこうしたプロジェクトの中でどのような役割を担うことになるでしょうか。
個人的には「プロジェクトマネージャ」をやるのがお勧めです。
なぜなら経営層がデータ分析人材に期待することは、「データ分析によって課題を解決すること」だからです。
分析レポートを作って提出すること、で終わりではありません。
そのため、データ分析の技術的なスキルだけではなく、プロジェクトマネジメントスキル、課題特定のスキル、提案や交渉のスキル、トラブルシューティングのスキルなど多様なスキルも必要になるでしょう。
コンサル企業だとデータ人材がこうした役割を担っていることも少なくないでしょう。
いやいやうちは事業会社だし、ひとりで黙々と分析レポートを作ってる方が好きなんだよ、という方などにはちょっとハードルが高いとか、あまりやりたくないなと感じられるかもしれません。
正直私自身も黙々と作業してる方が好きなので、そうした仕事が向いてるかと言われると微妙なのですが、いざやってみると新たなスキルアップの機会にもなりますし、不安はあれどまあなんとかやり切れるものだったりします。
ということで、データ分析人材の人にもプロジェクト化はおすすめです。